
기계학습
기계학습의 성능을 높이기 위해서는 특징을 잘 뽑아내는 것이 매우 중요
특징 벡터의 차원이 커질 수록 머신러닝의 성능은 높아질 가능성이 커지지만, 계산량이 많아져 속도가 느려지게 됨
-> 차원을 적당히 줄이기 위해 차원 감소 기법을 사용함.
카테고리
- 교사 학습
학습 데이터의 정확한 클래스가 알려져 있음
ex ) 강아지 고양이 분류
장점 : 결과를 사람이 검토해야 하는 비용이 비교사 학습에 비해 상대적으로 작음
단점 : 사람이 수작업으로 클래스를 입력 해야함

- 비교사 학습
학습 데이터의 정확한 클래스가 알려져 있지 않음.
장점 : 수작업으로 클래스 입력할 필요 없음
단점 : 수작업으로 결과를 검토해야 함

- 반교사 학습
교사 학습 + 비교사 학습
사람이 수작업으로 클래스 일부만 입력해도 되며, 모델의 결과를 자동으로 분석해줌

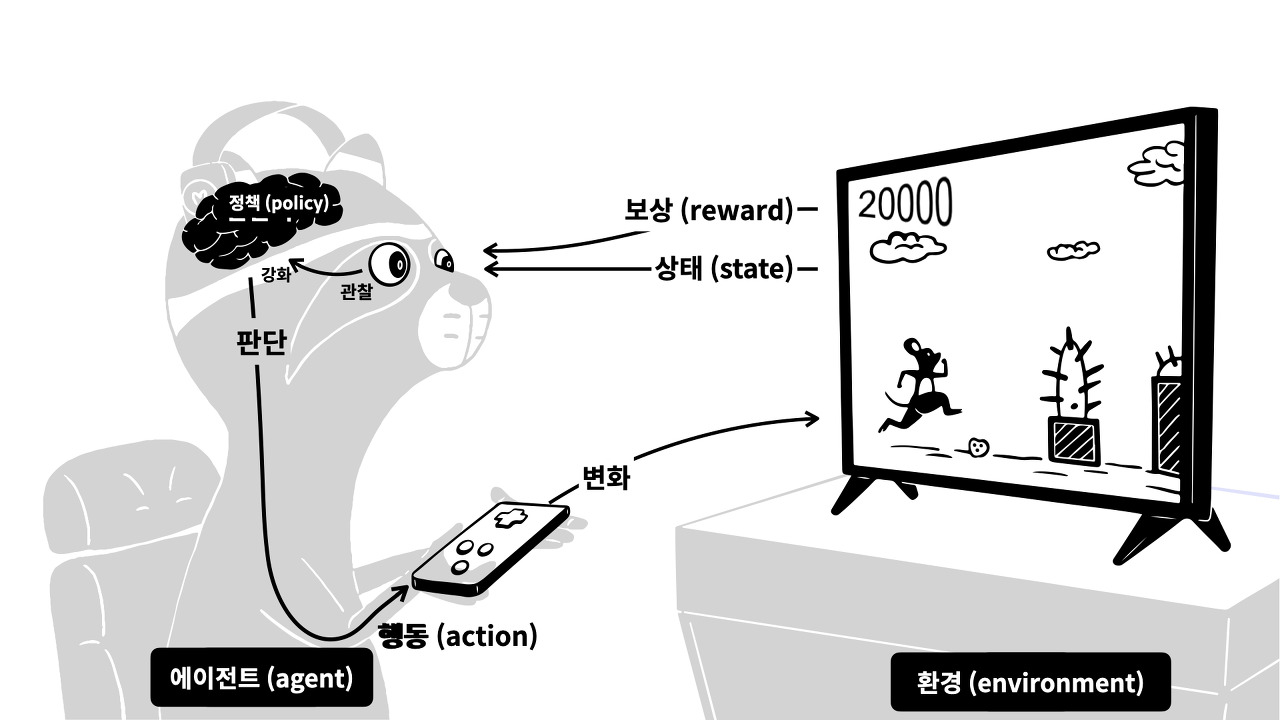
- 강화 학습
실패 -> 실패한 상황에 대한 피드백
성공 -> 보상
기계학습 기술 적용 분야
1. 분류 : 데이터로부터 클래스를 예측 - 이산/범주형 변수
가장 대중적인 분류 알고리즘 : 나이브 베이즈(Naive Bayes), 랜덤 포레스트, 서포트 벡터 머신
ex ) 일반종양/악성종양 , 스팸/비스팸, 긍정/부정
나이브 베이브 분류기를 이용한 간단한 텍스트 분류기 동작 과정
학습데이터 : 카테고리가 있는 뉴스 -> 나이브 베이즈로 모델 만듦
모델을 만들기 위해 단어의 확률 계산, 사전에 정의된 각각의 카테고리에 해당할 확률 구함
만들어진 모델을 테스트 데이터로 테스트 -> 성능 측정
성능이 만족하지 않을 경우, 알고리즘을 바꾸거나 특징을 바꿔야 함.2. 군집 : 데이터로부터 의미 있는 그룹을 나눔
가장 대중적인 군집 알고리즘 : k-means 군집, 계층적 군집
1) k-means
각 관측치가 가장 가까운 평균을 갖는 군집에 속하고, 군집의 초기 값 역할을 하는 k개의 군집으로 n개의 관측치를 분할
2) 계층적 군집
클러스터의 계측을 구축하고 찾는 클러스터 분석 방법
병합
bottom-up 접근 방법
시간 복잡도 O(n^3)분열
top-down 접근 방법
시간 복잡도 O(2^n)
3. 회귀 : 데이터 분석을 통해 값을 예측 - 실수/연속형 변수
하나의 변수 평균값과 다른 변수의 해당 값 간의 관계를 측정
변수 간의 관계를 추정하기 위한 통계적인 방법
대표적인 회귀 : 로지스틱 회귀
'데이터 > 머신러닝' 카테고리의 다른 글
| Naive Bayes(나이브 베이즈) (0) | 2022.06.30 |
|---|---|
| 적대적 머신러닝 - 학습 알고리즘 공격 모델 (0) | 2022.06.29 |
| 적대적 머신러닝 - 시큐어 학습을 위한 프레임워크 (0) | 2022.06.29 |
| 적대적 머신러닝 (0) | 2022.06.28 |